

次に「判別に関わる技術(目視判別の「脳」に関わる技術)」について説明します。
1. 判別における2つのステップ

画像処理により合否を判別するには、大きく2つのステップがあります。1つ目は「画像内で判別したい箇所を認識する」ステップ、2つ目は「認識した内容に対して合否の判別基準を定める」ステップです。
(1) 「画像内で判別したい箇所を認識する」ステップについて
画像処理による検査の最終的な目的は合否の判別ですが、合否判別の基準として「何に着目するのか」を定める必要があります。そのための工程が「画像内で判別したい箇所を認識する」ステップです。
画像処理による判別箇所の抽出には、大きく分けるとAI(ここでは、Deep Learningを用いた検査モードを「AI」と称します。)を用いた手法と、ルールベースと呼ばれる手法に二分されます。AIとルールベースの最大の違いは、検査箇所を抽出する基準を見つけるための調整をDeep Learningを用いてソフトウェアに任せる(AI)か、人が状況に応じて最適な判別手段を選択する(ルールベース)かです。
(2) 「抽出した箇所に対して合否の判別基準を定める」ステップについて
「画像内で判別したい箇所を認識する」ステップで設定した抽出内容に対し、合否の判別基準を設定します。判別基準には抽出した面積、個数、識別した文字列の内容等があります。
例えば、AIで検出対象を抽出した場合は、「見つけた対象の個数」に応じて合否判断を行い、ルールベースで例えば元の画像との比較し差分を抽出方法として選択した場合は「違いとして抽出した総面積」に応じて合否判断を行います。
2. AIとルールベースの違い
両判別技術には、それぞれ特徴と留意点があり、これらを理解した上で適切な画像処理の条件を設定する必要があります。
| ステップ | AI | ルールベース | |
| 判別箇所 抽出 | 特徴 | ・一義的に定義が難しい曖昧な箇所の抽出も可能 ・撮像環境が不均一でも判別箇所の抽出ができるケースもある ・人の操作は学習するデータ準備と抽出箇所の指示(アノテーション)のため、難しいツール選定が不要(アノテーションが不要なアルゴリズムもあります。) | ・判別箇所の抽出ルールが明確 ・抽出箇所の調整は、設定する数値の変更により任意に調整可能 ・簡単な判別箇所の抽出であれば、短時間で設定できる |
| 留意点 | ・抽出に至ったロジックが不明確 ・アノテーションと学習に依存し、抽出領域の調整が難しい ・学習用の画像準備に手間がかかる | ・複雑な抽出条件の定義は困難 ・画像の均一性(影がない、色が均一)や同一性(製品の変更による差がない)が必要 ・どのモードでどの抽出ができるのか一定の知見が必要 | |
| 判別基準 決定方法 | 特徴 | ・検出した個数、あるいは文字内容により判別 ・Scoreや合致度と呼ばれる指標により判別 | ・エッジ間のピクセル数、抽出領域の面積、個数、文字内容等から選択が可能 |
| 留意点 | ・面積やピクセル数といった定量的な大きさによる判別ができない | ・どのモードでどの判別基準を用いるのか一定の知見が必要 | |
3. 様々なAIアルゴリズム

一言に「AIによる判別」といっても実際には学習するデータの種類や、判別箇所の抽出方法によりいくつかの種類に大別されます。
(1) 学習するデータによる違い:良品を覚えさせる「教師無し学習」と不良品を覚させる「教師有り学習」
AIには良品の画像を学習し、学習した内容と異なる部分を不良部として判別する「教師無し学習」と、画像内の不良部を指定し、指定した不良部を学習する「教師有り学習」があります。「教師無し学習」は、不良品を準備する必要が無いこと、どのような不良が発生するかわからない場合でも良品として学習した特徴から異なれば不良として検出できます。そのため、準備の簡単さ、不良品を個別に設定する必要がないことからAIによる判別の最初のステップとして検討されるケースが多いアルゴリズムです。一方で、「教師無し学習」のアルゴリズムでは不良品を見逃してしまうケースや良品を不良品と誤判別してしまうケースでは、「教師有り学習」のアルゴリズムを用いることで検査精度を改善できる可能性があります。
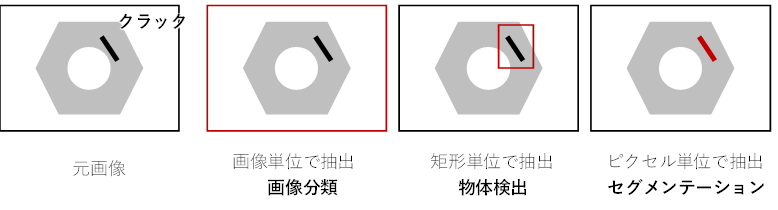
(2) 抽出する領域の違い:「画像分類」「物体検出」「セグメンテーション」
アルゴリズムにより得られる結果の違い:「画像分類」「物体検出」「セグメンテーション」
使用するアルゴリズムにより、判別により得られる結果もそれぞれ以下のように異なります。
画像分類:画像全体がどのような画像か判別(例:画像に対して、良品の画像、クラックの画像のように分類)
物体検出:画像内のどの位置に、いくつ、何があるのか矩形単位で判別(例:画像内のどこにクラックがあるのか矩形で抽出)
セグメンテーション:画像内のどの位置に、いくつ、何があり、どの程度の大きさなのかピクセル単位で判別(例:画像内にクラックが、どこに、いくつ、何ピクセルの大きさであるのかピクセル単位で抽出)
不良品を検出する多くの画像解析ソフトウェアは、抽出する対象の個数や大きさを確認したいため、物体検出(矩形で判別)かセグメンテーション(ピクセル単位で判別)が採用されています。ピクセル単位で抽出することにより、ルールベースのアルゴリズムと組み合わせて抽出したピクセル数による判別が可能なソフトウェアもあります。
また、これらのアルゴリズムは抽出箇所の指示(AIの用語でアノテーションと称します)方法にも大きく影響します。物体検出の場合は、抽出箇所を矩形で囲みますが、セグメンテーションの場合は、抽出箇所をピクセル単位で指定する必要があります。
セグメンテーションを用いることにより、ピクセル数によるサイズ判別が可能となることは一つのメリットですが、矩形で囲めばアノテーションが完了する物体検出は、セグメンテーション対比でアノテーション工数を削減できるメリットがあります。
4. AIによる学習の進め方

AIを用いた画像処理による判別を行う際は、以下のステップで判別するための条件設定を行います。
データ収集:判別基準として使用する画像データを収集します。
(アノテーション):教師有り学習のアルゴリズムを使用する場合、抽出箇所の指示を行います。
学習:収集したデータを用いて、判別箇所を抽出するためのディープラーニングにより作成される演算式(モデルと称します)を作成します。
評価・チューニング:学習に使用した画像、学習に使用していない画像をそれぞれ作成したモデルで評価を行い、最適な判別結果が得られるか確認します。多くの場合、最初は誤判別が発生するため、データ収集やアノテーションを再度行います。
5. まとめ
パソコンの性能向上や技術の進歩により外観検査工程での、画像解析技術の導入障壁は低くなりつつあります。一方で、「高い検査精度」で「簡単に操作できる」と謳われている画像解析技術が本当に自社の製品に対して最適な検査精度で、自社運用ができるのかという点を慎重に見極めることが必要です。